自动驾驶测试里程暴增,头部公司如何挖掘数据金矿?
发布日期: 2021-05-28来源: 汽车之心
千万公里级数据如何传输、存储和挖掘?
目前在全球范围内,L4 自动驾驶测试里程积累最多的公司是 Waymo。
Waymo 的前身是 Google X 下的无人车项目。
Waymo 用了将近 8 年时间完成了第一个 1000 万英里里程的积累,而第二个 1000 万英里积累用时仅 1 年零 3 个月。
这说明,随着车队规模增长和大范围测试开展,自动驾驶里程的增速将越来越快。
虽然目前全球完成千万公里级里程积累的自动驾驶公司只有 Waymo 和百度两家,但相信在今年和明年,会有越来越多的公司加入这一行列。
毫无疑问,数据是自动驾驶发展的金矿。
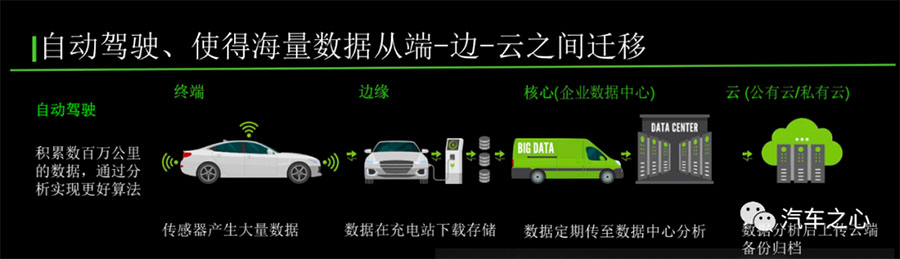
而面对如此大规模的数据,如何传输、存储和挖掘已经成为业内面对的新兴问题。
以往在自动驾驶算法训练的过程中,针对大容量车载数据的离线迁移,目前业界没有特别成熟的解决方案。
常见的做法是将车载计算平台中的固态硬盘取出来,再通过快递或人工手段,从训练场带到数据中心。」希捷科技中国区业务拓展经理董志南向我们分享。
「这样的做法可能传输效率比较低,运输过程容易损伤盘体造成数据丢失,不利于自动驾驶系统的快速开发迭代。」
为此,希捷在过去几年开发了一个 Lyve 系列的产品,这是一套「套娃式」的模块化存储硬件,从车载端覆盖到服务器端,来实现庞大数据量的转移和传输。
目前,丰田的自动驾驶子公司 TRI-AD 和捷豹路虎在爱尔兰的研发中心都在使用 Lyve DRIVE 进行自动驾驶系统的快速转移和存储。
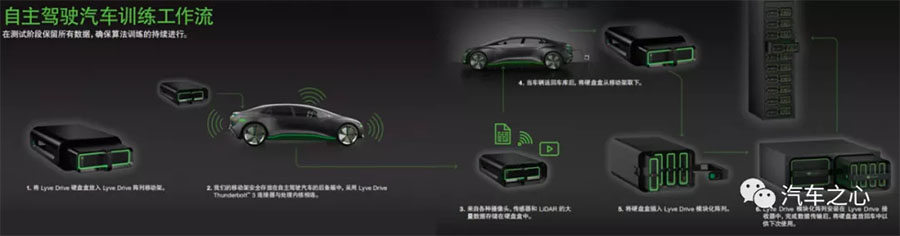
解决了转移和存储问题,下一步是如何从海量数据中挖掘出最有价值的数据。
「如果行驶场景是空无一人的大街,其实对算法训练没什么帮助。」希捷科技的董志南分享,「真正有价值的是一些非常少见的交通状况,比如红绿灯突然坏掉了,于是路口变成了由一个交警来进行指挥的场景。」
百度 Apollo 自动驾驶技术部总经理王云鹏将海量数据的数据挖掘工作总结为人工标注 - 离线挖掘- 在线挖掘三个阶段:
第一个阶段,通过车上的测试人员来记录问题,从而标记下那些出现问题的场景数据;
第二个阶段是离线挖掘,也就是数据回传到数据中心后,通过动态场景语义理解,给数据打上自动化的标签,在导入仿真场景库中进行大量的训练;
第三个阶段是在线挖掘,车端的系统通过动态条件出发,来主动采集和回传高价值的场景数据,从而减少大量数据存储和转移的工作。
通过这样的过程,车队开展规模化的路测,路测数据被快速传回数据中心,有价值的数据被挖掘出来,加速自动驾驶系统的高效迭代。
智能汽车时代更加需要「黑匣子」
一方面 L4 级的自动驾驶技术快速发展,最激进的公司可能希望在 5 年之内推动 Robotaxi 民用化。
另一方面,L2+的技术开始大规模上车。
特斯拉具有高速公路上下匝道、自动变道功能的 NOA 自动导航辅助驾驶就是典型的 L2+系统,蔚来汽车在 2020 年也推出类似的 NOP 功能,小鹏在 2021 年初推出 NGP。
此外,长城汽车、吉利汽车、理想汽车均有推出此类功能的计划。
在此基础上,华为更进一步,华为联合北汽极狐将在今年底交付的车型上,实现城市道路自动驾驶的高阶智能驾驶方案 ADS。
小鹏在 P5 上推出的 Xpilot 3.5 城市 NGP 功能也是类似方案。

这些自动驾驶系统的推出,改变了车辆上的传感器、计算平台部署以及电子电气架构设计,也大幅改变了汽车的软硬件成本结构。
同时,因为机器参与了车辆的驾驶过程,针对这些车辆的驾驶责任界定也正在发生变化。
